
This page explains how my regulation checker works, why it is structured the way it is, and how you can use or adapt it. It is published openly and is free to use.
The problem this is trying to solve
Large regulated documents such as Annual Reports are subject to hundreds of overlapping requirements. These include UK adopted IFRS, the Listing Rules (LR), the Disclosure Guidance and Transparency Regulations (DTR), governance codes, and narrative expectations that sit outside any single piece of legislation.
In practice, compliance is checked under severe constraints:
- The document is long and still changing late in the process
- Different teams own different sections
- Requirements are numerous, fragmented, and unevenly distributed
- Confidence drops as deadlines approach, because nobody can easily see coverage across the whole regulatory set
Manual checklists do not scale well. Informal reading is unreliable under time pressure. What is missing is a systematic, repeatable way of asking the same regulatory questions of a document every time it changes, and getting answers that are traceable back to the source text.
Why structure matters
After a lot of experimentation, the most important design decision turned out not to be the choice of AI model, but the structure imposed around it.
The only way I have found to do a comprehensive automated regulatory check is to break a long document into parts and assess those parts systematically against the full set of requirements. This is not because smaller parts are cleverer, but because structure constrains behaviour.
The model must never be allowed to assume it has seen the whole document. It must be forced to answer a narrow question repeatedly and consistently: does this specific section provide evidence for this specific requirement.
Everything else in the design flows from that principle.
High level workflow
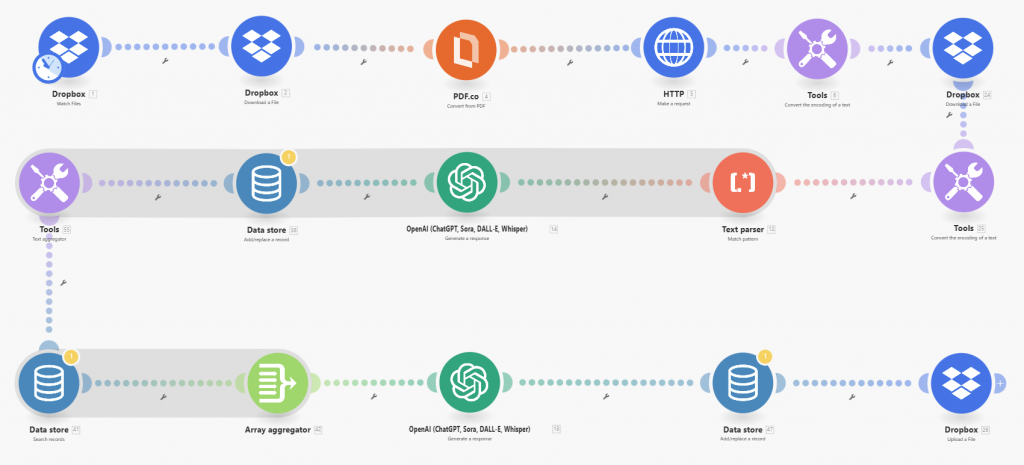
The checker is implemented as a Make.com scenario. At a high level it works as follows:
- Drop the long document you want reviewing into a Dropbox folder (or OneDrive)
- The document is extracted using pdf.co and split into multi-page sections
- A structured set of regulatory requirements is downloaded from Dropbox as input
- Each section is assessed independently against the full requirement set
- The output uploaded to Dropbox is machine readable and designed for aggregation and review
The aim is not to produce a single judgement on compliance, but to generate evidence that can be inspected, filtered, and discussed.
Document segmentation
The document is split into sections that are long enough to preserve narrative context but short enough to be processed reliably. These are typically several pages at a time, not single pages.
This is a deliberate compromise. Very small segments lose meaning. Very large segments encourage the model to infer coverage from elsewhere. Multi page sections preserve coherence while keeping the assessment bounded.
Each section is assigned a stable identifier so that results can be re-run and compared as drafts evolve.
Regulatory requirement structure
Requirements are supplied in a structured form, typically JSON or JSONL. Each requirement is represented explicitly rather than buried in prose.
A typical requirement includes:
- A unique requirement ID
- The regulatory source, for example IFRS, LR, DTR
- A clear statement of what disclosure or behaviour is expected
- Optional notes on scope or interpretation
This structure is critical. Vague or compound requirements produce vague outputs. Clear requirements produce assessable results.
The assessment prompt
The model is instructed to treat each section as isolated evidence. It is explicitly told:
- It is only seeing one section
- It must not assume information from elsewhere
- It must assess the strength of evidence, not guess intent
- Absence of evidence is a valid outcome
The output is constrained to a machine readable format. This prevents rhetorical answers and makes downstream analysis possible.
Typical outputs include:
- Requirement ID
- Assessment outcome, for example clearly addressed, partially addressed, not addressed
- Short reasoning grounded in the text
- Optional extracted quotations or references
Iteration and late-stage change
The scenario is designed to be re-run repeatedly as drafts change.
This is where it becomes useful in practice. When Finance updates numbers, when Legal tightens language, when sections move or expand, the same requirement set can be applied again without redesigning the process.
Because the logic is consistent, differences between runs are meaningful. Coverage improving or degrading is visible rather than anecdotal.
What this is and is not
This checker is not a substitute for legal judgement or formal sign off. It does not interpret intent or make compliance decisions in isolation.
What it does provide is a systematic way of reducing uncertainty. It answers the question teams actually worry about late in the process: have we checked everything, and can we see where the evidence sits.
Why this took time to build
Many obvious approaches feel like they should work and do not. Allowing the model too much freedom produces confident but unreliable outputs. Over constraining it produces brittle results.
The balance between document segmentation, requirement clarity, and prompt design took time to find. The final structure is intentionally boring. That is a feature, not a bug.
Availability and reuse
All of this is published openly and is free to use. Properly free. No gated demos, no black box outputs.
You are free to reuse the structure, adapt the requirement formats, or rebuild the scenario for your own regulatory context. If you work with long form regulated documents, you will recognise the problem space immediately.
Regulatory checking should be systematic, repeatable, and defensible. This is one practical way of getting there.
Applying agentic AI to real life problems can look daunting, so if you need some hand-holding on how to get started implementing this, please get in touch.
Resources:
- The Make.com scenario for the regulation checker
- A JSON file containing 152 of the required regulations for a UK listed company’s Annual Reports
- Output of a sample run using the Rolls Royce plc Annual Report for 2024. The output includes both the generated JSON output and a human readable version. You can the input file, the Rolls Royce plc Annual Report in pdf format, here.
Costs:
To get this working you need to subscribe to chatgpt, api.openai.com, pdf.co and Make.com. Make.com is flexible so you can substitute in other LLMs such as Gemini for chatgpt and api.openai.com.
The example file (Rolls Royce 2024 Annual Report) is 228 pages long. I calculate (roughly) that the costs to process this file once are as follows:
Make.com: $1.33 per 1000 credits. It used 92 credits. Cost ~ 10p
OpenAI API: Using Chatgpt5.2, Input $1.75/1M tokens, Output $14.00 /1M tokens. The process used a total of ~ 1.1m input and 110,000 output tokens giving rise to a cost of £2.57
Pdf.co: 11 credits cost $0.01 ~ £0.01
So the total cost per run is ~ £2.68
Fact Sheet: AI Regulation Checker Security & Privacy
- Zero-Retention Processing: By using the OpenAI API (rather than the consumer ChatGPT interface), data sent for analysis is not used to train OpenAI’s models.
- Encrypted Transit: All data moving between your PDF source, Make.com, and OpenAI is encrypted using industry-standard TLS 1.2+ protocols.
- Temporary Data Residency:
- Make.com: Data is processed in-memory. While “Data Stores” are used to hold chunk-level evidence, these can be configured to auto-delete after the final report is generated.
- OpenAI: API inputs are typically retained for 30 days only for abuse monitoring and are then deleted.
- No Public Indexing: Unlike web-based AI tools, your Annual Report text is never indexed by search engines or made part of a public database.
- Sovereignty: Users can select the data region for their Make.com organization (e.g., UK or EU) to satisfy local data residency requirements.